템플릿은 코딩 시간 절약, 코드 중복 회피의 두마리 토끼를 한꺼번에 잡아 준다.
하지만 아무 생각 없이 템플릿을 사용하면 코드 비대화(code bloat)가 나타날 수 있다. 이 코드 비대화를 어떻게 하면 방지할 수 있을까?
우선적으로 써 볼 수 있는 방법은, 공통성 및 가변성 분석(commonality and variability analysis)이다. 이름은 좀 거창해보이지만 사실 우리가 항상 해오던 분석 방법이다.
우리가 어떤 함수를 만들고 있다가 무심코 다른 함수를 봤는데, 지금 만들고 있는 함수 구현 중 일부가 다른 함수의 구현에도 똑같이 있다는 사실을 알아챘다고 가정해보자. 당연히 우리는 두 함수로부터 공통 코드를 뽑아내고, 이것을 별도의 새로운 함수에 넣은 후, 이 함수를 기존의 두 함수가 호출하도록 코드를 수정할 것이다.
이 이야기를 '공통성 및 가변성 분석'에 빗대어 다시 구성하면, 우리는 두 함수를 분석하여 '공통적인' 부분과 다른 부분을 찾을 후에 공통 부분은 새로운 함수에 옮기고 다른 부분은 원래 함수에 남겨둔 것이다.
템플릿을 작성할 때도 똑같다만, 단 한가지 주의해야 할 점이 있다. 템플릿이 아닌 코드에서는 코드 중복이 명시적이다. 두 함수 혹은 두 클래스 사이에 똑같은 부분이 있으면 눈으로 찾아낼 수 있다는 것이다.
반면, 템플릿 코드에서는 코드 중복이 암시적이다. 소스 코드에서는 템플릿이 하나밖에 없기 때문에, 어떤 템플릿이 여러 번 인스턴스화될 때 발생할 수 있는 코드 중복을 우리의 감각으로 알아채야 한다는 것이다.
예제를 보자. 고정 크기의 정방행렬을 나타내는 클래스 템플릿을 하나 만들고 싶다고 가정하자. 이 클래스 템플릿은 역행렬 만들기 연산을 지원한다.

이 템플릿은 T라는 타입 매개변수도 받고, size_t 타입의 비타입 매개변수(non-type parameter)인 n도 받도록 되어 있다. 비타입 매개변수는 타입 매개변수보다는 흔하지 않지만, C++ 문법에 적법하게 인정되는 매개변수이다. 이 예제처럼 자연스럽게 써도 된다.
그리고 다음의 코드를 보자.
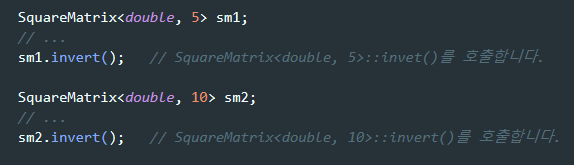
이제 invert의 사본이 인스턴스화되는데, 만들어지는 사본의 개수가 두 개이다. 이 둘은 같은 함수일 수가 없다. 왜냐하면 한쪽은 5x5 행렬에 대해 동작할 함수이고, 다른 쪽은 10x10 행렬에 대해 동작할 함수이기 때문이다. 그렇지만 행과 열의 크기를 나타내는 상수(n)만 빼면 두 함수는 완전히 똑같다. 이런 현상이 바로 템플릿을 포함한 프로그램의 코드 비대화의 원인이다.
사용하는 값이 5와 10인 것만 다르고 나머지는 모두 똑같은 두 함수가 눈에 띈다면 어떻게 할까?
=> 그 값을 매개변수로 받는 별도의 함수를 만들고, 그 함수에 5와 10을 매개변수로 넘겨서 호출하게 만든다.
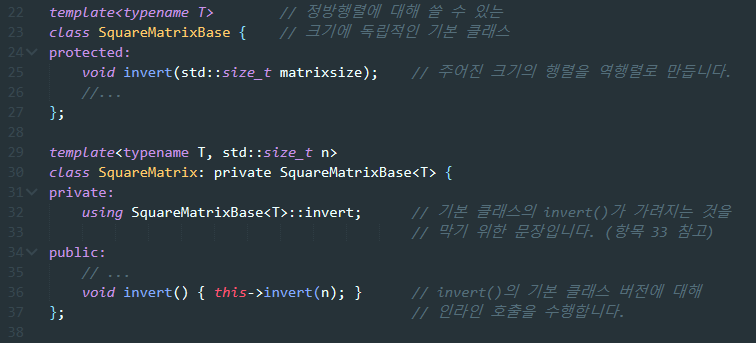
행렬의 크기를 받는 invert() 함수를 기본 클래스인 SquareMatrixBase에 넣었다. SquareMatrixBase가 템플릿인 이유는 행렬의 원소 타입에 대해서만 템플릿화되어 있는 것이고, 행렬의 크기는 매개변수로 받지 않는다는 것이 SquareMatrix와 다르다.
따라서 같은 타입의 객체를 원소로 같는 모든 정방행렬은 오직 한 가지의 SquareMatrixBase 클래스를 공유하게 된다. 즉, 같은 원소 타입의 정방행렬이 사용하는 기본 클래스 버전의 invert()도 오직 하나의 사본이라는 말이다. (위의 예제에서 원소 타입은 double로 같았지만 함수 사본이 2개가 된 것과는 대조적이다.)
SquareMatrixBase::invert()는 오직 파생 클래스에서 코드 복제를 피하려는 용도로 만든 것이기 때문에 protected(상속계통에서만 접근가능)으로 되어 있다는 점도 체크하자. 그리고 이 함수를 호출하는 추가 비용을 없애기 위해 파생 클래스의 invert()에서 암시적으로 인라인 호출을 요청하였다.
또, 이 함수의 본문을 보면 "this->" 라는 표기가 있다. 항목 43에서 이야기한, 템플릿화된 기본 클래스의 맴버 함수 이름이 파생 클래스에 가려지는 문제를 피하기 위함인데, 이미 using 선언이 있으므로 딱히 필요 없긴 하다. 둘 중 하나를 택해서 사용하자.
SquareMatrixBase와 SquareMatrix 사이의 상속 관계가 private인 점도 놓치지 말자. 이는 단순히 SquareMatrixBase가 SquareMatrix의 구현을 돕기 위한 것 외엔 아무 의미가 없기 때문이다.(private 상속은 is-implemented-in-terms-of 관계이다. 항목 39 참고)
아직 해결 못한 문제가 하나 있는데, SquareMatrixBase::invert() 는 자신이 상대할 데이터가 어떤 것인지 어떻게 알 수 있을까? 정방행렬의 크기는 매개변수로 받으니 상관없지만, 진짜 행렬을 저장한 데이터가 어디에 있는지 어떻게 알까? 이 정보는 파생 클래스밖에 모를 것인데,,, 기본 클래스쪽에서 역행렬을 만들 수 있도록 '정방행렬의 메모리 위치'를 파생 클래스가 기본 클래스 쪽으로 어떻게든 넘겨주면 될 것 같다.
한 가지 방법은 SquareMatrixBase::inver()가 매개변수를 하나 더 받도록 하는 것이다. (예를 들어 행렬 데이터가 들어 있는 메모리의 시작 주소 포인터) 이 방법도 물론 좋지만, SquareMatrix의 함수 중 invert()처럼 행렬 크기에 상관없는 동작방식을 가져서 SquareMatrixBase에 그 본체가 있는 함수들이 invert() 하나만 있는게 아니라 여러 개가 있다면, 그 함수들도 싹 다 매개변수를 하나씩 더 달아줘야 한다. 이것은 귀찮기도 하고 SquareMatrixBase에게 똑같은 정보(행렬 데이터 포인터)를 되풀이 해서 알려주는 꼴이기 때문에 설계 상 좋지 못한 듯 하다.
다른 방법을 알아보자. 행렬 데이터가 있는 메모리에 대한 포인터를 SquareMatrixBase가 저장하게 하는 것이다. 그리고 포인터를 저장하는 김에 행렬 크기도 저장하자. 결과적으로는 다음과 같은 설계가 나올 것이다.

이렇게 설계하면, 메모리 할당 방법의 결정 권한이 파생 클래스 쪽으로 넘어간다. (기본 클래스의 생성자를 파생 클래스 생성자가 호출하니까) 파생 클래스를 만드는 사람에 따라, 행렬 데이터를 SquareMatrix 객체 안에 데이터 맴버로 직접 넣을 수도 있다.
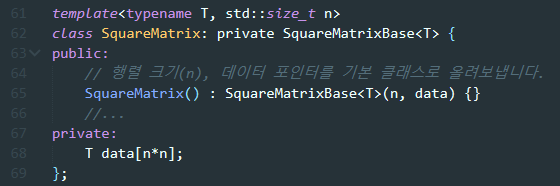
또는 각 행렬의 데이터를 힙에 둘 수도 있다.

이렇게 어느 메모리에 데이터를 저장하느냐에 따라 설계가 다소 달라질 순 있지만, 핵심은 코드 비대화 방지의 측면에서 매우 효과적이라는 것이다.
- SquareMatrix에 속해 있는 맴버 함수 대부분이 기본 클래스 버전을 호출하는 단순 인라인 함수가 된다.
- 똑같은 타입의 데이터를 원소로 갖는 모든 정방행렬들이 행렬 크기에 상관없이 기본 클래스 버전의 사본 하나만을 공유한다.
- 그럼에도 행렬 크기가 다른 SquareMatrix 객체(파생 클래스 객체)는 저마다 고유의 타입을 갖고 있다.
물론 이런 장점들이 공짜는 아니다.
행렬 크기가 미리 녹아든 상태로 별도의 버전이 만들어지는 invert(), 그리고 행렬 크기가 함수 매개변수로 넘겨지거나 객체에 저장된 형태로 다른 파생 클래스들이 공유하는 버전의 invert(), 이 둘을 비교하면 전자가 후자보다 더 좋은 코드를 생성할 가능성이 높다.
예를 들어, 크기별 고정 버전(전자)의 경우, 행렬 크기가 컴파일 시점에 투입되는 상수(템플릿 매개변수는 컴파일 타임에 바인딩된다.)이기 때문에 상수 전파(constant propagation)1 등의 최적화가 먹혀 들어가기 좋다.
반면, 여러 행렬 크기에 대해 한 가지 버전의 invert()만 두도록 만들면 실행 코드의 크기가 작아진다. 이를 통해
- 프로그램의 작업 세트 크기가 줄어든다. -> 명령어 캐시 내의 참조 지역성이 향상된다.
- 이로 인해 프로그램 실행 속도가 빨라진다.
전자가 좋을지 후자가 좋을지는 사용하는 플렛폼 및 대표 데이터 집합에 대해 두 방법을 모두 적용해보고 그 결과를 판단하는 수 밖에 없다.
효율에 대해 생각한다면 객체의 크기도 고려할 요소이다. invert와 비슷한 크기 독립형 버전의 함수를 기본 클래스쪽으로 아무 생각 없이 옮겨 놓다 보면, 나도 모르는 새에 객체의 크기가 늘어나있을 수 있다. 방금 본 코드를 보면 SquareMatrix 객체는 메모리에 생길 때마다 SquareMatrixBase 클래스에 들어있는 데이터를 가르키는 포인터(SquareMatrixBase::pData)를 하나씩 떠안고 있다. 파생 클래스 자체에 이미 이 데이터에 접근할 수 있는 수단(SquareMatrix::pData)이 있는데, 결국 SquareMatrix 객체 하나의 크기는 최소한 포인터 크기 하나만큼 낭비된 것이다.
조금만 고민하면 이런 포인터가 필요없도록 설계할 수 있지만, 설계를 바꾸더라도 얻는게 있으면 잃는게 있다는 사실을 잊으면 안된다. 예를 들어, 기본 클래스로 하여금 행렬 데이터의 포인터를 protected 맴버로 저장하게끔 만들면 항목 22에서 설명한 캡슐화 효과가 날아간다.(기본 클래스에 protected로 pData를 하나만 놔둬 파생 클래스가 이를 접근하게 하는 방법인데, 결국 private->protected로 변경된 만큼 캡슐화 효과는 기대하기 힘들다는 말이다.)
그뿐 아니라 자원 관리에서도 골치 아픈 일이 일어날 수 있다. 만약 행렬 데이터의 포인터를 저장하는 일은 기본 클래스에서 담당하게 하되, 실제로 이 데이터를 저장할 메모리를 동적(또는 정적으로라도)할당하는 일은 파생 클래스쪽에서 하도록 맡긴다면, 포인터를 삭제할지 말지는 어떤 식으로 결정해야할까?
이런 고민들은 조금 수고하면 해결할 수는 있겠지만, 상황을 더 복잡하게 할 수도 있다는 것이다. 웬만큼 파고들다가는 차라리 그냥 코드 중복을 허용하는 편이 싸게 먹힐 수가 있다.
이번 항목에서는 비타입 플릿 매개변수로 인한 코드 비대화만을 다뤘으나, 타입 매개변수도 코드 비대화의 원인이 될 수 있다. 예를 들어, 상당수의 플렛폼에서 int와 long은 이진 표현구조가 동일하다. 그래서 이를테면 vector<int> 와 vector<long>의 맴버 함수들은 완전히 똑같을 수 있다. -> 코드 비대화이다. 어떤 링커들은 이렇게 동일한 표현구조를 가진 함수들을 합쳐 주기도 하지만, 그렇지 않은 링커들도 있다.
정리하자면, int와 long에 대한 인스턴스화는 '어떤 환경'에서는 코드 비대화가 일어날 수도 있다는 것이다. 비한 예가 포인터 타입인데, 어지간한 대부분의 플랫폼에서 포인터 타입은 똑같은 이진 구조를 지니고 있기 때문에
- list<int*>, list<const int*>, list<SquareMatrix<long, 3>*>
이런 템플릿들은 이진 수준에서만 보면 맴버 함수 집합 하나면 충분하다. 이 말을 기술적으로 풀어 보면, 타입 제약이 엄격한 포인터(즉 T* 포인터)를 써서 동작하는 맴버 함수를 구현할 때는 하단에서 타입미정(untyped, 즉 void* 포인터)ㅗ 동작하는 버전을 호출하는 식으로 만든다는 말이다. 실제로 C++ 표준 라이브러리의 몇 개 구현 제품이 vector, deque, list 등의 템플릿에 대해 이런식으로 동작하고 있다.
우리도 만약 템플릿 설계하면서 코드 비대화를 고민해야 한다면, 이와 같은 생각을 해보는게 어떨까?
- 템플릿을 사용하면 비슷비슷한 래스와 함수가 여러 벌 만들어진다. 따라서 템플릿 매개변수에 종속되지 않은 템플릿 코드는 비대화의 원인이 된다.
- 비타입 템플릿 매개변수로 생기는 코드 비대화의 경우, 템플릿 매개변수를 함수 매개변수 혹은 클래스 데이터 맴버로 대체함으로써 비대화를 종종 없앨 수 있다.
- 타입 매개변수로 생기는 코드 비대화의 경우, 동일한 이진 표현구조를 가지고 인스턴스화되는 타입들이 한 가지 함수 구현을 공유하게 만듦으로써 비대화를 감소시킬 수 있다.
-
상수 전파 : + 컴파일 시 상수를 포함하는 연산이 계산될 수 있으면, 계산하여 코드를 줄임
- x=3.14; y=2*x;
- y를 계산할 때까지 x값이 변하지 않는다면, compile time에 y=6.28로 변환
'Effective C++ > 7. 템플릿과 일반화 프로그래밍' 카테고리의 다른 글
| 항목 43: 템플릿으로 만들어진 기본 클래스 안의 이름에 접근하는 방법을 알아두자. (0) | 2021.05.19 |
|---|---|
| 항목 42: typename의 두 가지 의미를 제대로 파악하자 (0) | 2021.05.16 |
| 항목 41: 템플릿 프로그래밍의 천릿길도 암시적 인터페이스와 컴파일 타입 다형성부터 (0) | 2021.05.14 |


