클래스 하나가 맘에 안들어서 소스 코드 한 줄을 수정했다. 인터페이스도 아니고 구현부인데다가 외부에 노출도 안되는 코드이다. 컴파일하는데 몇 초 안걸릴 거 같다. 빌드를 눌렀다. 느낌이 이상하다. 한참을 기다려도 빌드가 안끝난다. 엄;
문제의 핵심 : C++는 인터페이스와 구현의 분리가 깔끔하게 안되있다. 정확히 말하면 이 둘을 분리하는 문법적 장치같은것이 없음 => 사용자가 알아서 분리해야함
C++의 클래스 정의(class definition)은 클래스 인터페이스만 지정하는 것이 아니라 구현까지 상당히 많이 지정하고 있다.
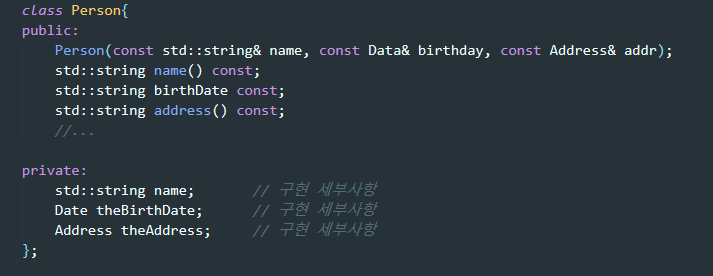
위 코드만 가지고는 Person 클래스가 절대 컴파일되지 않겠다. => string, Date, Address가 어떻게 정의됬는지 모르기 때문이다. => 이들의 정의를 어디선가 가져와야 한다. => #include
클래스를 정의하는 코드에 보면 그래서 #include를 많이 쓴다.
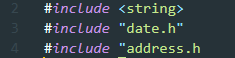
=> 얘네가 골칫덩이임. Person을 정의한 파일과 위 헤더파일 사이의 dependency(컴파일 의존성)가 생김
=> 위 헤더 파일 3개중 하나만 바뀌어도, 또는 이들과 또 엮여있는 헤더 파일이 바뀌기만 해도, Person 클래스를 정의한 파일을 코 꿰이듯 컴파일러에게 끌려감 => 심지어 Person을 사용하는 다른 파일들 까지 몽땅 다시 컴파일 해야 한다.
그럼 왜 C++ 이렇게 클래스 정의 안에 구현 세부사항들이 들어가는걸 방치하냐? 이게 어떤 이득인데?
=> 그러니까 이런식으로 하게 하면 안되나?(Person을 정의할 때 구현 세부사항을 따로 떼어서 지정하는 식으로)
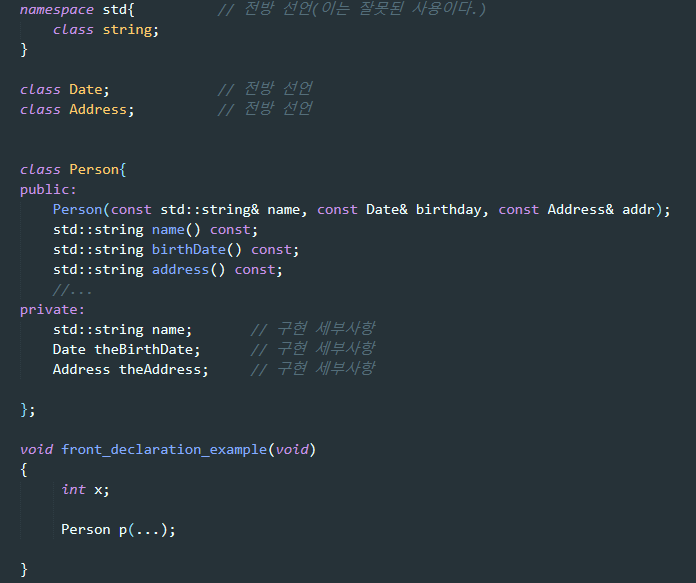
이게 만약 되면, Person 사용자는 Person 클래스의 인터페이스(구현이 아님!)이 바뀌었을 때만 컴파일을 다시 하면 되니 정말 좋을 것 같다..
이 코드의 문제점
- string은 사실 class가 아니라 typedef로 정의한 타입동의어이다.(typedef basic_string<char> string)
string은 근데 #include만 해도 왠만하면 컴파일 시 병목현상(이것때메 컴파일 시간 오래걸림)을 일으키지 않는다. 표준라이브러리 헤더는 그냥 #include만 해도 괜찮음, 특히 빌드 환경이 사전 컴파일 헤더(precompiled header)를 쓸 수 있으면 더 상관 없다.
- 컴파일러가 컴파일 도중에 객체들의 크기를 전부 알아야 한다는 것이다.!
저 코드에서 컴파일러가 Date의 크기를 알 방법이 있을까? 알려면 무조건 date.h에서 알야아 한다. => 저렇게 전방선언으로 타입을 미리 알려줘도 어짜피 date.h를 다시 컴파일되야 함
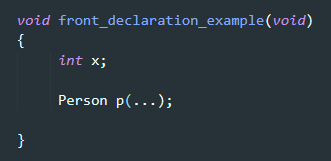
여서서 컴파일러는 x와 p 객체가 정의되어있으니 이 둘의 메모리공간을 Stack에 할당해야함. => x의 크기는 int(기본정의타입)이니 4byte인걸 알건데, p의 크기는 어떻게 아나? => Person의 정의를 살펴봐야함 => 만약 Person에서 구현 세부정보(데이터 객체)가 없다고 해도 컴파일러가 Person의 정의 확인하기 전까지 그걸 어떻게 아냐 => 어짜피 Person의 정의를 확인해야 하고 => 어짜피 컴파일 다 해야됨
======================================================================
Smalltalk나 java의 경우 이런 고민을 할 필요가 없는게, 저 상태에서 Person이 뭔지 몰라도 일단 컴파일은 되기 때문이다. => 이들 언어에선 객체가 정의될 때 컴파일러가 그 객체의 포인터(포인터는 기본제공타입이다.)를 담을 공간만 할당하면 되기 때문이다.
=> 이 방법을 그대로 C++로 가져오면 문제를 해결할 수 있다. '포인터에 실제 객체 구현부 숨기기'
클래스를 두 클래스로 쪼개자. 하나는 인터페이스만 제공, 하나는 인터페이스의 구현
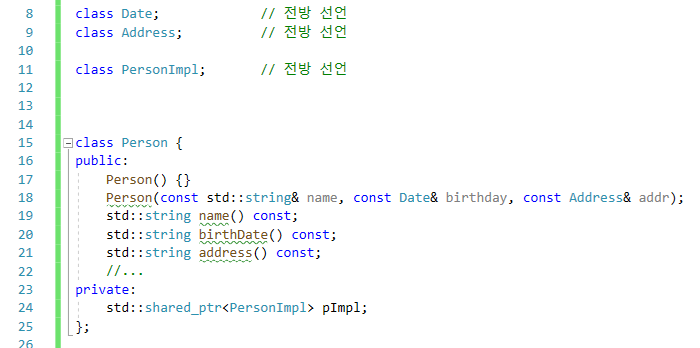
인터페이스 제공 : Person
인터페이스 구현 : PersonImpl
그리고 Person에 PersonImpl의 스마트 포인터 하나를 넣는다.
=> pimpl idiom 이라고 하는 설계 패턴이다.
이렇게 설계해두면, Person의 사용자는 생일, 주소, 이름 등의 자질구례한 세부사항과 완전히 갈라서게 된다.
=> Person의 구현 클래스는 맘대로 고칠 수 있고, Person의 사용자 쪽에선 컴파일을 다시 할 필요가 없다. 그리고 Person이 어떻게 구현되있는지 사용자는 알 방법이 없기 때문에 구현 세부 사항에 어떻게든 발을 걸치는 코드를 작성할 여지도 없어진다.
=> 이렇게 인터페이스와 구현으로 나누는 열쇠는 '정의부에 대한 dependency'를 '선언부에 대한 dependency'로 바꾸는 것이다.
즉, 헤더파일을 만들 때는 실용적으로 의미를 갖게 한 자체조달(self-sufficient, 그 자체로 뜻을 지니는) 형태로 만들고, 정 안되면 다른 파일에 대해 dependency를 갖도록 하되, 정의부가 아닌 선언부에 대해 의존성을 갖도록 하자.
이것이 파일 의존성을 최소화 하는 핵심 원리이다.
그리고 이것을 핵심 전략으로 하고, 그 외의 전략들을 보자. 어짜피 위의 말과 비슷한 이야기들
- 객체 참조자 및 포인터로 충분한 경우에는 객체를 직접 쓰지 않는다.
어떤 타입에 대해 참조자 및 포인터를 정의할 때는 그 타입의 선언부만 필요하다. 반면, 어떤 타입의 객체를 정의할 때는 그 타입의 정의가 있어야 한다.
- 할 수 있으면 클래스 정의 대신 클래스 선언에 최대한 의존하도록 만든다.
어떤 클래스를 사용하는 함수를 선언할 때는 그 클래스의 정의를 가져오지 않아도 된다. 심지어 그 클래스 객체를 값으로 전달하거나 반홚더라도 클래스 정의가 필요 없다.

물론 call by value가 좋진 않지만(항목 20 참조), 피치 못할 사정 때문에 써야할 때도 있을 건데, 이런 경우에도 불필요한 컴파일 의존성을 끌고 들어면 안된다.
clearAppointments()를 사용자가 호출할 때는 Date의 정의가 필요할 것이다. 근데 왜 굳이 사용안할 거 같은 함수를 선언해놓나? => 호출하는 사람이 모두가 아니기 때문이다.
우리가 어떤 라이브러리를 사용한다고 해서 거기 있는 모든 함수들을 사용하는 것이 아니다. 그래서 함수 선언이 되어있는 헤더 파일에는 부담을 주지 않고, 실제 사용자에게 부담을 전가하는 방법을 사용한다. 이렇게 하면 실제 쓰지도 않을 타입 정의에 대해 사용자가 의존성을 끌고 오는 거추장스러움을 막을 수 있다.
- 선언부와 정의부에 대해 별도의 헤더 파일을 제공한다.
"클래스를 둘로 쪼게자" 라는 지침을 잘 활용할려면 헤더 파일을 두개 만들고, 관리도 짝 단위로 관리해야 한다. 그리고 사용자 쪽에선 전방 선언을 하지 않고, 선언부만 #include 하고, 라이브러리 제작자 쪽에선 헤더 파일 2개를 짝으로 제공하는 일을 잊으면 안된다.
=> 3번째 전략의 의미를 진짜 모르겠는데, 내가 생각하기엔 이거다. 라이브러리를 사용하다보면 정의가 아니라 선언만 필요할 때가 있다. 이럴 경우를 대비해 선언만 별도 제공하는 헤더파일을 하나 만들어 주자. 그러면 라이브러리 사용자는 단지 전방선언만을 위해 정의가 포함된 엄청난 크기의 정의부 헤더파일을 인클루드 할 필요가 없어진다.
======================================================================
위의 Person 같은 클래스를 가르켜 핸들 클래스(handle class)라고 한다. 진짜 객체(PersonImpl)에 대한 핸들(Pointer)만 데이터 맴버로 가지는 클래스이다. 이를 활용하는 예제를 보여주면
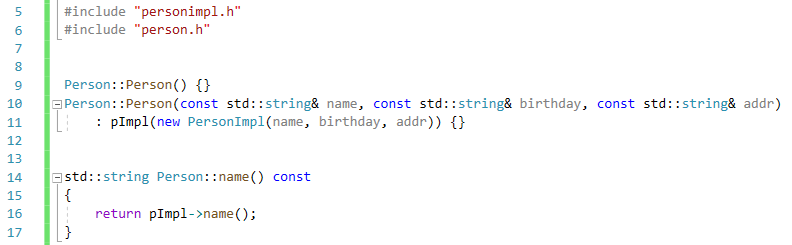
이런으로 Person의 멤버 함수들을 정의할 때, Person에서 뭘 할려고 하지말고 실제 객체인 PersonImpl에 모든 기능을 실제로 구현해놓고, Person에선 단지 PersonImpl에서 똑같이 작동하는 함수를 호출하는 방법을 사용하자.
======================================================================
핸들 클래스가 싫다면, 인터페이스 클래스(interface class)를 만드는 것도 한 방법이다. 어떤 기능을 나타내는 인터페이스를 abstract base class로 만들어 놓고, 이 클래스로부터 파생 클래스를 만들 수 있게 하자는 거다.
인터페이스 클래스는 단지 derived 되는게 목표이기 때문에, 데이터멤버도 없고, 생성자도 없고, 단지 가상 소멸자와 인터페이스를 구성하는 순수 가상 함수들만 있다.
C++에선 인터페이스 클래스에 딱히 제약이 없다.(자바 처럼 인터페이스에 데이터 멤버 추가가 불가능한거나그런게 없음) => 이런 특징이 유용하게 쓰일 때가 있다. 항목 36을 참고하면 비가상 함수의 구현은 주어진 클래스 계통 내의 모든 클래스에 대해 똑같아야 한다. => 비가상 함수는 인터페이스 클래스의 일부로서 구현해두는 편이 이치에 맞다.
Person 클래스의 인터페이스 클래스는 다음과 같이 만들어볼 수 있다.
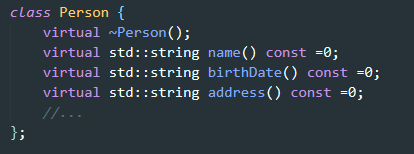
이 클래스를 코드에 써먹을려면, Person에 대한 포인터 혹은 참조자(핸들)로 프로그래밍 하는 방법 밖에 없다. => 나중에 자세한 얘기를 함
그리고 중요한 특징이, 인터페이스 클래스의 인터페이스가 수정되지 않는 한 사용자는 다시 컴파일할 필요가 없다.(핸들 클래스도 마찬가지임)
또한 인터페이스 클래스를 사용하기 위해서는 객체 생성 수단이 최소 하나는 있어야 한다. => 보통 파생 클래스의 생성자 역할을 대신하는 어떤 함수(팩토리 함수, 또는 가상 생성자라고 부름). 이 함수의 역할은 주어진 인터페이스 클래스의 인터페이스를 지원하는 객체를 동적 할당한 후, 그 객체의 포인터(스마트 포인터가 좋다, 항목 18 참고)를 반환하는 것이다. 그리고 대게 이런 함수는 인터페이스 클래스 내부에 정적 멤버로 선언되는 경우가 많다.
그냥 예를 보면 이해가 빠르다.
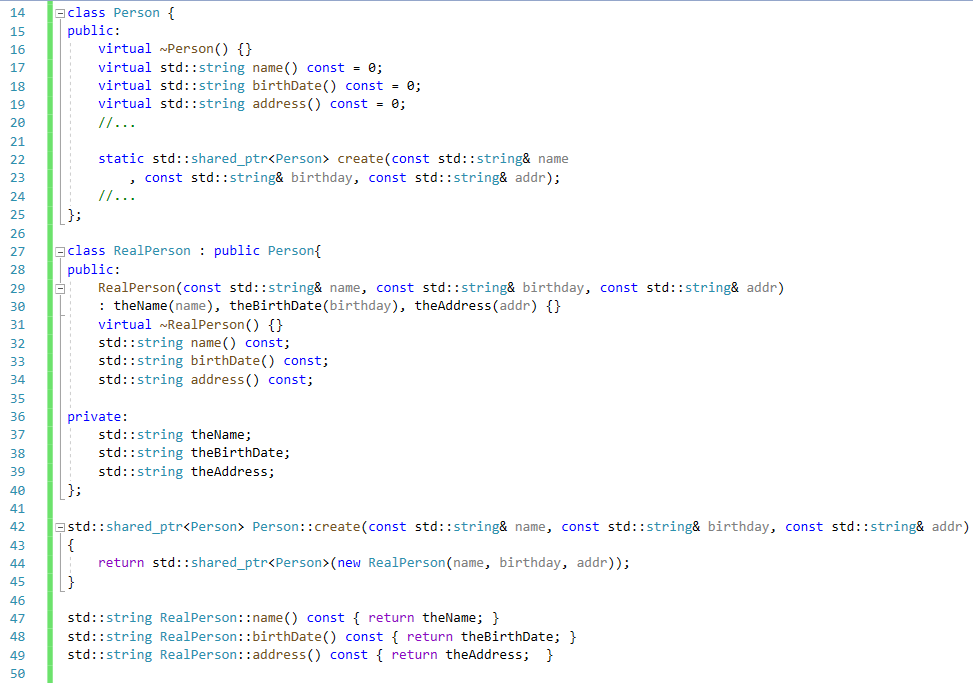
Person = 인터페이스 클래스, RealPerson = 인터페이스의 구현 클래스
지금 create가 무조건 RealPerson 인스턴스를 만드는 것으로 되어 있는데, 좀 더 현장 느낌에 가깝게 만들려면 함수 인자를 하나 더 받아서, 조건에 맞게 다양한 타입(Person 인터페이스를 사용하는, 즉 상속받는)의 인스턴스를 만드는 방법이 있다.
======================================================================
- 컴파일 의존성을 최소화 하는 작업의 배경이 되는 가장 기본적인 아이디어는 '정의' 대신 '선언'에 의존하게 만들자는 것이다. 이 아이디어에 기반한 두 가지 접근 방법은 핸들 클래스와 인터페이스 클래스 이다.
- 라이브러리 헤더는 그 자체로 모든 것을 갖추어야 하며 선언부만 갖고 있는 형태여야 한다. 이 규칙은 템플릿이 쓰이거나 쓰이지 않거나 동일하게 적용하자.
'Effective C++ > 5. 구현' 카테고리의 다른 글
| 항목 30: 인라인 함수는 미주알고주알 따져서 이해해 두자. (0) | 2021.04.24 |
|---|---|
| 항목 29: 예외 안전성이 확보되는 그날 위해 싸우고 또 싸우자! (0) | 2021.04.24 |
| 항목 28: 내부에서 사용하는 객체에 대한 '핸들'을 반환하는 코드는 되도록 피하자. (0) | 2021.04.24 |
| 항목 27: 캐스팅은 절약, 또 절약! 잊지 말자 (0) | 2021.04.24 |
| 항목 26: 변수 정의는 늦출 수 있는 데까지 늦추는 근성을 발휘하자 (0) | 2021.04.24 |



